The Future of Enterprise Data Warehousing: Mesh vs. Lakehouse
An analytical deep dive comparing decentralized Data Mesh paradigms with centralized Unified Data Lakehouses, outlining key trade-offs for scaling teams.
Dr. Kavya Reddy
An analytical deep dive comparing decentralized Data Mesh paradigms with centralized Unified Data Lakehouses, outlining key trade-offs for scaling teams.
Core Concepts
The Future of Enterprise Data Warehousing: Mesh vs. Lakehouse
For decades, the central data warehouse was the holy grail of corporate intelligence. We loaded transactional logs into monolithic databases, built massive ETL pipelines, and hoped for a single source of truth. But as data scale exploded and organizations diversified, this centralized model hit a wall: it became a bottle-neck managed by a single, overwhelmed IT team.
Today, enterprise architects stand at a crossroads between two dominant architectures: the Data Lakehouse and the Data Mesh.
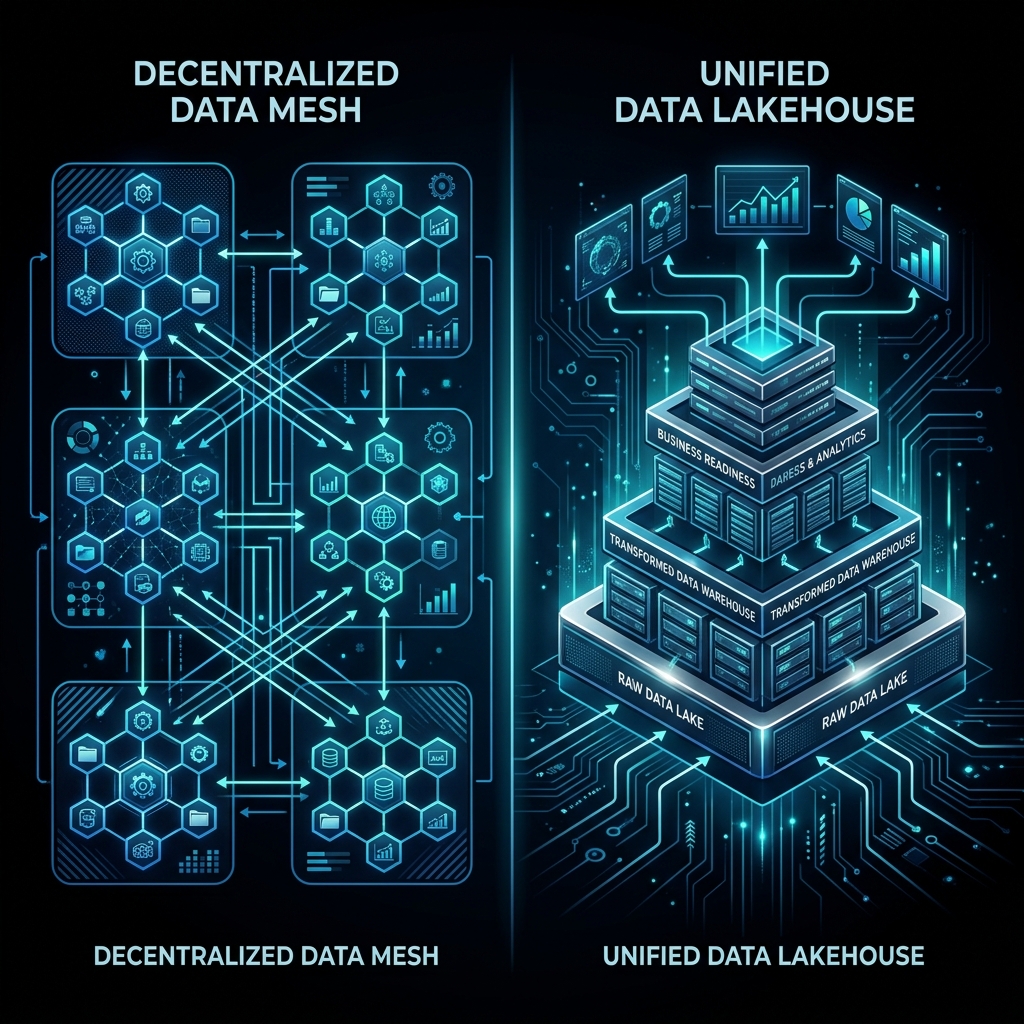
1. The Unified Data Lakehouse: Centralized Power
The Data Lakehouse combines the best elements of data lakes and data warehouses. It stores vast amounts of unstructured, raw data at low cost (like a lake) while providing structured query capabilities, ACID transactions, and schema enforcement (like a warehouse).
- Core Technologies: Delta Lake, Apache Iceberg, Apache Hudi, and modern cloud warehouse platforms.
- Key Advantage: A single physical storage layer where both BI analysts (using SQL) and data scientists (using Python) can query the same data simultaneously.
- Trade-off: Still relies on a centralized repository, which can lead to domain friction if a single team is responsible for ingestion, modeling, and cleanups.
2. The Data Mesh: Decentralized Autonomy
Data Mesh is not a specific technology, but a socio-technical philosophy. It posits that data should be managed by the specific business domains that generate it (e.g., the billing team owns the billing data, the marketing team owns the web event data). Data is treated as a "product" and served via standardized APIs or catalogs.
- Core Concepts: Domain ownership, data-as-a-product, federated computational governance, self-serve data platform.
- Key Advantage: Incredible organizational scalability. Teams can move fast and create data products without waiting for a central data team.
- Trade-off: High organizational overhead. It requires strong governance standards to prevent different departments from creating incompatible data schemas.
DataParametrics Recommendation
For mid-market and scaling enterprises, a Hybrid Approach is often most successful. We recommend establishing a physical Data Lakehouse structure to keep storage costs low and queries fast, but organizing data stewardship and ownership along Data Mesh domain boundaries.
Standardizing definitions in a centralized semantic compiler (like dbt) allows business units to maintain autonomy over their models while guaranteeing metric alignment.
Strategic Outlook
Organizations that treat data as a product consistently outperform those that treat it as a byproduct.
— DataParametrics Research Practice
Architecture Comparison
| Feature | Centralized | Decentralized | Hybrid |
|---|---|---|---|
| Governance | Unified | Domain | Federated |
| Scalability | Moderate | High | High |
| Cost Control | Low | Complex | Balanced |
| Latency | Low | Variable | Low |
| Compliance | Simple | Distributed | Policy-as-code |
Core Principles
Privacy by Design
Compliance built into architecture, not added post-launch.
Performance First
Sub-second query engines with elastic auto-scaling clusters.
Data Sovereignty
Full control over data residency, access, and retention.
Discovery Audit
Inventory all databases, classify workloads, and map existing pipelines.
Architecture Design
Define schema standards, network topology, and governance policies.
Engineering Build
Develop secure pipelines, deploy infrastructure, integrate controls.
Quality Verification
Run automated data quality checks and performance benchmarks.
Production Release
Cut-over with zero downtime, monitor, and decommission legacy systems.
Strategic Recommendation
For mid-market enterprises, a hybrid architectural approach consistently delivers the highest ROI within the first 18 months of deployment.
Combine a physical data lakehouse backbone with domain-driven governance boundaries. Standardize metric definitions in a semantic layer to ensure alignment across all business units.
Key Takeaways
Treat data as a product with clear ownership boundaries and quality SLAs.
Combine physical lakehouse storage with domain-driven governance for optimal results.
Privacy engineering must be embedded at the architecture layer, not retrofitted.
Automate compliance monitoring with policy-as-code to reduce manual overhead.
Use a semantic layer to standardize metric definitions across all business units.
Continue Reading
Related Research

Deploying Generative AI Safely Behind Enterprise Firewalls
A complete structural blueprint for deploying private large language models and vector search databases without exposing confidential IP.

Privacy-First Analytics: Engineering for Modern Data Protection
How modern analytics teams can capture customer usage trends and product metrics while maintaining strict compliance with evolving privacy rules.

Modern Lakehouse Architectures for Enterprise Scale
An architectural analysis of modern Lakehouse deployments, data product design, governance frameworks, and scalability considerations for global organizations.